最近看网上的一些视频想到一个新的方法进行练习,我可以用手机或者pad播放一个声部,然后我弹另一个声部,因为这样可以把节奏练得非常准确,而且因为一次只弹一个声部,练习效率应该会提高很多。先试试吧,后面在回顾总结。
关于轮指
分组练习,而不是想要一次性尽量地快速而持久,你的目的是让你自己更加放松。
关于震音
最近看网上的一些视频想到一个新的方法进行练习,我可以用手机或者pad播放一个声部,然后我弹另一个声部,因为这样可以把节奏练得非常准确,而且因为一次只弹一个声部,练习效率应该会提高很多。先试试吧,后面在回顾总结。
关于轮指
分组练习,而不是想要一次性尽量地快速而持久,你的目的是让你自己更加放松。
关于震音
门内的晶体管的转换需要一定的时间,这意味着门输入的变化需要一定的时间来引起输出的变化。
例如,在NLDM模型下,Gate delay = f (input transition (slew) time, output load Cnet+Cpin),其中Cnet是之线网电容负载,Cpin是驱动单元的引脚电容。
单元时序模型用于为电路设计中存在的各种器件单元提供准确的时序。时序模型数据通常是从单元的电路仿真中获得的,用来模拟单元操作的实际场景。
以一个简单反向器的时序弧举例。对于反向器,如果输入端的上升跃迁将会导致输出端的下降跃迁,反之亦然。 因此,单元有两种类型的延迟:输出上升延迟和输出下降延迟。
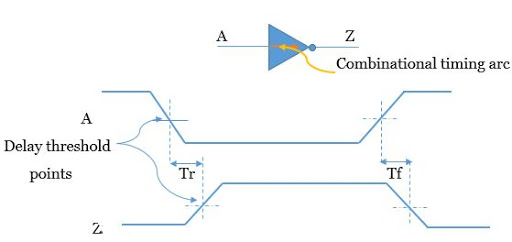 |
|---|
| 反向器的Timing arc delay |
这些延迟是根据库中定义的阈值测量的,该阈值通常为 Vdd 的 50%。因此,延迟是从输入阈值点到输出阈值点的时间来测量的。
反向器的timing arc delay取决于两个因素:输出负载(输出端的电容负载)和输入端的转换时间。延迟值与负载电容成正比——负载电容越大,延迟越大。在大多数情况下,延迟随着输入转换时间的增加而增加,并且在某些情况下,cell的延迟可能表现出相对于输入转换时间的非单调行为,这意味着较大的输入转换时间可能会产生较小的延迟,特别是如果输出负载很高的话。
输出端的转换时间与输出电容成正比,即输出转换时间随着输出负载的增加而增加。因此,根据cell类型及其输出负载,输入端的较大的转换时间可能降低输出端的转换时间,而输入处较小的转换时间也会使输出端转换时间变大。下图中显示了两种情况,其中cell 输出端的转换时间会随着输出端的负载而改善或恶化。
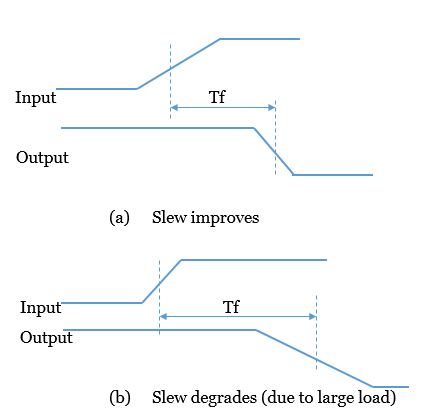
在此,单元的延迟和输出转换时间表示为两个参数的线性函数:输入转换时间和输出负载电容。
线性延迟模型的一般形式是
D = D0 + D1 S + D2 C
其中 D0、D1、D2 是常数,S 是输入转换时间,C 是输出负载电容。
线性延迟模型在深亚微米技术下的输入转换时间和输出电容范围内并不准确,因此目前大多数单元库使用更复杂的模型,如非线性延迟模型 (NLDM) 和 CCS 模型。
如今,非线性延迟模型(NLDM)或基于复合电流源时序模型(CCS)的查找表(LUT)被广泛用于静态时序分析(STA)。在这些 LUT 中,单元延迟和转换时间等特征数据由固定数量的输入转换时间和负载电容值索引。
Synopsys Liberty (.lib) 格式文件,也称为时序库文件(Lib 文件),包含多种用于计算单元延迟的 LUT。通常Lib文件是由代工厂提供的,但是当设计者想要拥有自己的单元库或者在过程中改变一些参数时,他需要自己生成lib文件。所以设计人员应确定决定输入转换时间和输出负载的工艺特征参数,然后通过 Hspice 仿真或其他 EDA 工具获取时序信息。
在完成整个库的表征后,设计人员需要自己分析时序文件的准确性,以备日后工作,目前没有任何 EDA 工具可以自动分析。整个时序分析的准确性取决于时序文件中cell中使用的延迟模型的准确性。
另外,LUT 只包含固定数量的参数,例如 5x5 或 7x7(输入转换时间和负载)对的大小,而其他对的延迟是使用线性插值获得的。因此,在制作自己的标准单元库时,选择合适的输入转换时间和负载的特征参数是时序库文件准确性的关键工作。
NLDM 是一种高度准确的时序模型,因为它源自 SPICE 特性。大多数单元库使用表模型来指定单元的各种时序弧的延迟和时序检查,表模型称为 NLDM,用于计算延迟、输出转换或其他时序检查。该表给出了单元输入引脚输入转换时间和单元输出总输出电容的在各种组合下的cell单元延迟。NDLM 延迟模型以二维形式表示,其中两个独立变量是输入转换时间和输出负载电容,表中的条目表示延迟。一些较新的时序库还为深亚微米技术提供了基于当前源(例如 CCS、ECSM 等)的高级时序模型。
这与来自引脚 INP1 和 OUT 的逆变器时序弧的上升和下降延迟模型以及引脚 OUT 上允许的最大转换时间相关,用于输出引脚的上升和下降延迟的独立时序模型,它们分别表示为 cell_rise 和 cell_fall。
pin (OUT) {
max_transition: 1.0;
timing () {
related_pin: "INP1";
timing_sense: negative_unate;
cell_rise (delay_template_3x3) {
index_1 ("0.1, 0.3, 0.7"); /* Input transition */
index_2 ("0.16, 0.35, 1.43"); /* Output capacitance */
values (/* 0.16 0.35 1.43 */ \
/* 0.1 */ "0.0513, 0.1537, 0.5280", \
/* 0.3 */ "0.1018, 0.2327, 0.6476", \
/* 0.7 */ "0.1334, 0.2973, 0.7252");
}
cell_fall (delay_template_3x3) {
index_1 ("0.1, 0.3, 0.7"); /* Input transition */
index_2 ("0.16, 0.35, 1.43"); /* Output capacitance */
values ( /* 0.16 0.35 1.43 */ \
/* 0.1 */ "0.0617, 0.1537, 0.5280", \
/* 0.3 */ "0.0918, 0.2027, 0.5676", \
/* 0.7 */ "0.1034, 0.2273, 0.6452");
} 在查找表模板中指定了两个变量,表中的第一个变量是输入转换时间,第二个变量是输出电容,但这可以是其中表示方法,第一个变量也可以是输出电容;但通常一个库中设计人员使用一致的模板。这种在查找表中表示延迟的形式称为非线性延迟模型,因为延迟随输入转换时间和负载电容的非线性变化。
NLDM 模型不仅用于输出延迟,还用于由输入转换时间和输出负载表征的输出转换时间。这也分离了用于计算单元输出上升和下降转换时间的二维表。这些由输出中的rise_transition 和fall_transition 表示。
pin (OUT) {
max_transition: 1.0;
timing () {
related_pin: "INP";
timing_sense: negative_unate;
rise_transition (delay_template_3x3) {
index_1 ("0.1, 0.3, 0.7"); /* Input transition */
index_2 ("0.16, 0.35, 1.43"); /* Output capacitance */
values (/* 0.16 0.35 1.43 */ \
/* 0.1 */ "0.0417, 0.1337, 0.4680", \
/* 0.3 */ "0.0718, 0.1827, 0.5676", \
/* 0.7 */ "0.1034, 0.2173, 0.6452");
}
fall_transition (delay_template_3x3) {
index_1 ("0.1, 0.3, 0.7"); /* Input transition */
index_2 ("0.16, 0.35, 1.43"); /* Output capacitance */
values (/* 0.16 0.35 1.43 */ \
/* 0.1 */ "0.0817, 0.1937, 0.7280", \
/* 0.3 */ "0.1018, 0.2327, 0.7676", \
/* 0.7 */ "0.1334, 0.2973, 0.8452");
}
. . .
}
. . .
}具有非线性延迟模型的逆变器单元具有下表:
Rise delay
Fall delay
Rise transition
Fall transition
指定单元正在反转的信息在哪里?
该信息在时序弧的timing_sense 字段中指定。对于逆变器,时序弧为negative_unate,即输出引脚方向与输入引脚方向相反(负)。因此,cell_rise 表查找对应于输入引脚的下降转换时间,cell_fall 表查找对应于输入引脚的上升转换时间。
case 1:当输入转换时间和输出负载值与查找表索引值匹配时。
根据延迟表,输入下降转换时间 0f 0.3ns 和输出负载 0.16pf 将对应于 0.1018ns 的反相器上升延迟,因为输入端的下降转换使反相器输出上升。
fall_transition (delay_template_3x3) {
index_1 ("0.1, 0.3, 0.7"); /* Input transition */
index_2 ("0.16, 0.35, 1.43"); /* Output capacitance */
values (/* 0.16 0.35 1.43 */ \
/* 0.1 */ "0.0817, 0.1937, 0.7280", \
/* 0.3 */ "0.1018, 0.2327, 0.7676", \
/* 0.7 */ "0.1334, 0.2973, 0.8452");
}case 2:当输入转换时间和输出负载值与表索引值不匹配时
如果时序路径上的任何端口/网络超过了超出 LUT 范围的值,STA 工具将从现有 LUT 表中推断出所需的值。但是,线性插值方法并不能保证外插值的准确性。
该示例与查找表不对应表中任何可用条目。在这种情况下,使用二维内插来计算结果延迟值。为每个维度中的表插值选择两个最接近的值。
考虑 0.14ns 输入转换和 1.15pF 输出电容的下降转换查找表。下面为二维插值给出的下降过渡表再现如下。
fall_transition (delay_template_3x3)
index1 (“0.1, 0.3 . . .”);
index2 (“. . . 0.35, 1.43”);
values (\
“. . . 0.1937, 07280” \
“. . . 0.2327, 0.7676”
. . . 输入转换时间 0.14ns 位于 0.1ns 和 0.3ns 输入转换之间,因此我们假设 0.1ns 是 x1,0.3ns 是 x2,0.14ns 是 x0。类似地,输出负载 1.15pF 位于 0.35 和 1.43 输出负载之间,因此我们假设 0.35 是 y1,1.43ns 是 y2,1.15 是 y0,相应的延迟条目是 T11 = 0.1937、T12=.07280、T21=.22607。 .
如果(x0, y0)需要查表,则通过插值得到延迟值T00,公式为:
X1= 0.1, x2= 0.3 和 x0 =0.14
y1= 0.35, y2=1.43 和 y0= 1.15
T11 = 0.1937、T12=.7280、T21=.2327 和 T22=0.7676。
xo1 = (x0 – x1) / (x2 – x1) = (0.14 – 0.1) / (0.3 – 0.1) = 0.04/0.2 = 0.2
x2o = (x2 – x0) / (x2 – x1) = (0.3 – 0.14) / (0.3 – 0.1) = 0.16/0.2 = 0.8
y01 = (y0 – y1) / (y2 – y1) = (1.15 – 0.35) / (1.43 – 0.35) = 0.8/1.08 =.7407
y20 = (y2 – y0) / (y2 – y1) = (1.43 – 1.15) / (1.43 – 0.35) = .28/1.08 =.3651
T00 = x20 * y20 * T11 + x20 * y01 * T12 + x01 * y20 * T21 + x01 * y01 * T21
替换值
T00 = 0.8 0.3651 0.1937 +0.8 0.7407 .7280 + 0.2 0.3651 .2327 + 0.2 0.7407 0.7676
= 0.056575 + 0.43138 + 0.01699 + 0.11371
= 0.6186
该等式对于内插和外推均有效(当索引 (x0, y0) 位于索引 1 和索引 2(索引的特征范围)之外时)。
例如,对于 index1 为 0.05 和 index2 为 1.7 的查找表,则下降过渡值获得为:
X1= 0.1, x2= 0.3 和 x0 =0.05
y1= 0.35, y2=1.43 和 y0= 1.7
T11 = 0.1937、T12=.7280、T21=.2327 和 T22=0.7676。
xo1 = (x0 – x1) / (x2 – x1) = (0.05 – 0.1) / (0.3 – 0.1) = - 0.05/0.2 = -0.25
x2o = (x2 – x0) / (x2 – x1) = (0.3 – 0.05) / (0.3 – 0.1) = 0.25/0.2 = 1.25
y01 = (y0 – y1) / (y2 – y1) = (1.7 – 0.35) / (1.43 – 0.35) = 1.35/1.08 =1.25
y20 = (y2 – y0) / (y2 – y1) = (1.43 – 1.7) / (1.43 – 0.35) = -0.27/1.08 = -0.25
T00 = x20 y20 T11 + x20 y01 T12 + x01 y20 T21 + x01 y01 T21
=1.25 (-0.25) 0.1937 + 1.25 1.25 .7280 + (-0.25) (-0.25) 0.2327 + (-0.25) 1.25 0.7676
= 0.8516
原文:https://www.physicaldesign4u.com/2020/05/non-linear-delay-model-nldm-in-vlsi.html
静态时序分析的目的是验证设计是否符合规定的时序约束,同时基于时序分析的结果,在不满足的情况下决定如何修改优化来满足对应的时序约束。
主要包括网表
通常是lef/def/liberty 等文件
记录了timing arc的信息
反标的寄生数据 parasitic文件。
主要是记录逻辑器件和器件之间的连线延时。
布局布线之后通常是通过Wireload Model根据橡皮面积的预估大小以及连续驱动组件数目的大小来决定连线的电阻和电容值,STA软件则利用这些电阻电容值来计算连线延迟。
时钟描述、边界条件、timing exception.

检查timing violations和constraints violations
例如,对于反向器的cell来说,时序弧的取决于output load和input transition time. 通常来说input transition time时间越大,output load越大,delay越大。

D0, D1, D2 are constants, S is the input transition time, and C is the output load capacitance.


计算精度较高,synopsys 工艺库主要采用的模型。非线性延时计算模型提供两种计算延时的方法。
一种是通过逻辑门转换时间和输出端负载电容值作为索引,通过查找表得到相应的数据,并通过插值计算得到延时。
一种是通过逻辑门传播时间(propagation time)和输出端负载电容值作为索引,通过查表得到数据,并通过插值计算先得到逻辑门传播延时和逻辑门转换延时,在根据共识D(cell) = D(propagation) + D(transition)
一般是输入到输出的延迟,上升、下降。



时序类型的cell的延时包含几种,同步的ck-D, 还有传输的ck-q, 以及ck-到CDN这样的异步的。


什么是正则表达式?
正则表达式(英语:Regular Expression,常简写为regex、regexp或RE),又称正则表示式、正则表示法、规则表达式、常规表示法。
它是一个字符串,可以用来描述、匹配一系列匹配某个句法规则的字符串。他描述的是一种正则文法,是一种上下文无关的文法。
例如: a*bc* 这样一个正则表达式可以匹配的是下面一些字符串:
b
ab
abc
aabc
aabcc
........
满足正则表达式的字符串是一系列满足文法规则的字符串集合。
大体上正则表达式有四类用途:
匹配查找
例如服务器出现故障的时候,我们需要从服务器的日志文件里面找出符合要求的相关事件信息 event1, event2,我们经常会使用 notepad++ 结合 正则表达式 event1|event2,把相关的事件都找出来,然后再做分析。
替换
在编写代码过程中,想要把所有的Size变量名都替换为iSize, 但是又不想修改像WindowSize 这样的变量名。 我们经常会使用 \bsize\b 来表达找到前后都是空白符的size
分割
找到日志中的日期,并且将其中的月份和日期打印出来,我们可以使用正则表达式的捕获分组功能来完成 (\d{4})-(\d{2})-(\d{2})
验证
网页前端需要校验用户输入的邮箱地址是否符合要求,可以使用^([a-zA-Z0-9._%-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,4})*$ 来提示用户输入是否正确。
正则表达式是一门语言,语言是由基本语法单元组成。正则表达式的基本单元主要包括下面几类:
字符、字符组、量词、捕获分组、断言组成。
字符区分为普通字符和元字符。
元字符就像是一门语言的语言关键字一样,他是有特殊含义的,只不过在正则语言里面的关键字是一些字符。元字符主要包括下面这些
| 元字符 | 描述 |
|---|---|
| . | 句号匹配任意单个字符除了换行符。 |
| [ ] | 字符集。匹配方括号内的任意字符。 |
| [^ ] | 否定的字符组。匹配除了方括号里的任意字符 |
| * | 匹配>=0个重复的在*号之前的字符。 |
| + | 匹配>=1个重复的+号前的字符。 |
| ? | 标记?之前的字符为可选. |
| {n,m} | 匹配num个大括号之前的字符或字符集 (n <= num <= m). |
| (xyz) | 字符分组,匹配与 xyz 完全相等的字符串. |
| | | 多选结构,匹配符号前或后的子表达式. |
| \ | 转义字符,用于匹配一些保留的字符 [ ] ( ) { } . * + ? ^ $ \ | |
| ^ | 从开始行开始匹配. |
| $ | 从末端开始匹配. |
所有的除了元字符以外的字符,可以称之为普通字符。例如数字:0-9,字母:a-z, A-Z , 符号:+ 等
当我们使用例如 abc 这样一个正则表达式的时候,正则表达式引擎一般是按照a->b->c->匹配这样一个单字符比较的方式来匹配的。
实际使用中字符组是最常用的语法结构之一。字符组就是一组字符。它表示的是在一个位置可以出现的各种字符,写法就是在[ 和] 之间列出所有可能出现的字符,例如[abc] ,[314], [#.?] 。
如果想要表示所有数字字符: [0123456789]
想要表示所有的小写字母: [abcdefqhijklmnopqrstuvwxyz]
需要注意的是:如果[]里面包含空格,那空格也是可选的字符之一
范围表示法就是使用 [x-y] 这种形式表示x到y的整个范围内的字符。范围表示法一般是根据字符对应的ascii 码值来确定的,ascii码值小的要放在前面。
例如:
[0123456789] --> [0-9]
[abcdefqhijklmnopqrstuvwxyz] --> [a-z]
注意:使用[0-z]这样的范围表示是合法的,但是他的范围很难一眼看出来。实际上从ascii码可以知道他表示的不仅仅包括数字、小写字母,还包括大写字母和其他的标点符号。
在[] 里面[ 紧跟着^ 就是排除型字符组,表示匹配一个没有来的字符。需要注意的是排除型字符组必须要匹配一个字符。
例如:
[^0-9] 表示 0-9之外的字符,也就是非数字字符。
[^0-9][0-9] 表示的是首个字符是非数字,第二个字符是数字。
8 不满足这个正则表达式, a8则满足
对于[0-9] [a-z] 等这样的常用字符组,正则表达式提供了简写的表达,例如我们可以使用:
\d 表达[0-9],其中的 d 代表"数字 (digit) ";
\w 表达 [Q-9a-zA-Z] ,其中的 w 代表"单词字符 (word) ";
\s 表达[ \t\r\n\v\f] (中括号里面第一个字符是空格), s 表示"空白字符(space)"
字符组简记法
| 简写 | 用法 |
|---|---|
\b |
匹配一个单词边界,也就是指单词和空格间的位置。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。 |
\B |
匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。 |
\cx |
匹配由x指明的控制字符control + x。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的“c”字符。 |
\d |
匹配一个数字字符。等价于[0-9]。 |
\D |
匹配一个非数字字符。等价于[^0-9]。 |
\f |
匹配一个换页符。等价于\x0c和\cL。 |
\n |
匹配一个换行符。等价于\x0a和\cJ。 |
\r |
匹配一个回车符。等价于\x0d和\cM。 |
\s |
匹配任何空白字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。 |
\S |
匹配任何非空白字符。等价于[^ \f\n\r\t\v]。 |
\t |
匹配一个制表符。等价于\x09和\cI。 |
\v |
匹配一个垂直制表符。等价于\x0b和\cK。 |
\w |
匹配包括下划线的任何单词字符。等价于“[A-Za-z0-9_]”。 |
\W |
匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。 |
如果我们想要在字符组里面使用-,^,[] 这样的元字符怎么办?
答案是使用转义符号\, 例如[a\-c] 表示的是 a \ c 这三个字符, [\^ab] 代表的是^ab 三个字符, [ 带包的是\[\]cz][]az四个字符
对于- 来说还可以将- 放在中括号最前面来表示。例如[-ab] 代表匹配的是 - a b 这三个字符
需要注意的是:很多语言本身就支持转义字符,所以要想传给正则表达式引擎合适的转义字符,通常需要使用raw string 避免转义. 例如python 可以使用 r"^[0\-9]$" 它等价于 "^[0\\-9]$". 其它不支持raw string 就需要用双重转义。
text = r'C:\Windows\System32\new'
patstr = r'[\\n]' # 或者 '[\\\\n]'
pattern = re.compile(patstr)
matches = pattern.finditer(text)
for i in matches:
print(i.group())
"""
\
n
\
\
n
"""量词可以用来表达前面的字符结构需要重复多少次。
例如,我们的手机号码一般是11位数字,我们可以使用\d\d\d\d\d\d\d\d\d\d\d 来表达,但是使用量词表达11位数字可以更简洁和直观:\d{13} (注:实际手机号码是有合法号段的)
量词一般可以按照如下的格式来写
| 量词 | 说明 |
|---|---|
| {n} | 之前的元素必须出现 n 次 |
| {m,n} | 之前的元素最少出现 m 次,最多出现 n 次 |
| {m,} | 之前的元素至少出现 m 次,出现次数无上限 |
| {0, n} | 之前的元素可以不出现,也可以出现,最多出现 n 次〈在某些语言中可以写为{, n}) |
{m,n} 是通用形式的量词,正则表达式还有三个常用量词,分别是*, +, ?·它们的形态虽
然不同于{m,n}, 但是功能相同 。
常用量词
| 常用量词 | {m,n}等价形式 | 说明 |
|---|---|---|
| * | {0,} | 可能出现,也可能不出现,出现次数没有上限 |
| + | {1,} | 至少出现 次,出现次数没有上限 |
| ? | {0,1} | 至多出现 次,也可能不出现 |
例如:
abc{2} 匹配的字符串是abcc
[abc]{2}匹配的字符串是aa, bb, cc
(abc){2}匹配的字符串是abcabc
分组是将正则表达式拆分为多个不同的部分,每个部分使用() 括起来表示是一个分组。分组主要的作用有下面几个:
将某些部分描述为分组,然后对分组运用量词,可以实现描述重复某个模式的字符串的功能。
利用分组和|形成多选结构
引用分组
利用分组分割
例如,(AT){3,10} 用来描述 AT 重复3次到10次的序列,如ATATAT, ATATATAT,.......
使用| 可以表达多个正则项里面匹配一个,一般|需要和()一起使用,表示分组里面的每一个项是可选的
例如 ^(From|To|Mail).* 可以用来匹配 From、To、Mail开头的行
使用括号不仅可以将有联系的元素归拢起来并分组,正则表达式还可以保存()分组匹配的文本,在正则表达式后面通过\groupnum来引用。
例如 <title>.*</title> 可以用来描述html里面的title 标签。 通过引用分组 <(title)>.*</\1> 更加简介;
例如 使用<([a-zA-Z0-9]+) (\s[^>]+)?>[\s\S]*?</\1> 可以匹配所有合法的html标签
注意:分组的编号是按照左括号出现的顺序来计数的。
例如:(((\d{4})-(\d{2}))-(\d{2})))
编号 : 123 4 5
例如,分割邮箱地址里面的id和服务商
mail = 'zch921005@126.com'
regex = '(\w{4,20})@(126|qq|gmail|163|outlook)\.(com)'
print(re.match(regex, mail).group(1))
'zch921005'
print(re.match(regex, mail).group(2))
'126'
对于正则表达式引擎来说,只要出现了括号,他都会将这个分组记录下来,但是如果不需要引用,保存这些分组必然会影响匹配执行的性能。所以正则表达式提供了一种方法来表示不需要捕获该分组: (?:....) 在括号的前面加上?:。
需要注意的是:如果使用了非捕获分组,注意分组编号是会忽略非捕获分组的。
例子 (?:\d{4})-(\d{2})-(\d{2}) 第一个捕获分组对应的是月份。
正则表达式中有一些结构并不是用于匹配文本,而是用于判断文本是否处于特点的位置。常用的断言包括:单词边界、行起始和结束位置。
单词边界:\b
行起始位置:^
行结束位置: $
环视是在当前位置看看左边或者的字符串是否满足条件,它并不匹配实际的字符串。
例如:
| 符号 | 描述 | 判断方向 | 匹配成功返回值 |
|---|---|---|---|
| ?= | 肯定顺序环视 | 右边 | True |
| ?! | 否定顺序环视 | 右边 | False |
| ?<= | 肯定逆序环视 | 左边 | True |
| ?<! | 否定逆序环视 | 左边 | False |
正则表达式:"(T|t)he(?=\sfat)"
The fat cat sat on the mat.
正则表达式:(T|t)he(?!\sfat)
The fat cat sat on the mat.
正则表达式:(?<=(T|t)he\s)(fat|mat)
The fat cat sat on the mat.
正则表达式:(?<=(T|t)he\s)(fat|mat)
The cat sat on cat。
字母数字字符:^[a-zA-Z0-9]*$
带空格的字母数字字符:^[a-zA-Z0-9 ]*$
密码:^(?=^.{6,}$)((?=.*[A-Za-z0-9])(?=.*[A-Z])(?=.*[a-z]))^.*$
电子邮件:\b[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,}\b
IPv4 地址:^((?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?))*$
小写字母:^([a-z])*$
大写字母:^([A-Z])*$
网址:\b(https?|ftp|file)://[-A-Z0-9+&@#/%?=~_|$!:,.;]*[A-Z0-9+&@#/%=~_|$]
日期(MM/DD/YYYY):^(0?[1-9]|1[012])[- /.](0?[1-9]|[12][0-9]|3[01])[- /.](19|20)?[0-9]{2}$
日期(YYYY/MM/DD):^(19|20)?[0-9]{2}[- /.](0?[1-9]|1[012])[- /.](0?[1-9]|[12][0-9]|3[01])$正则表达式所使用的理论模型是有穷自动机,其具体实现称为正则引擎 (Regex Engine) 。用正则表达式处理字符串,首先需要生成自动机〈很多语言中使用正则表达式之前都要"编译"正则对象);之后,无论输入什么字符串,正则引擎都只需要老老实实地在状态之间游走。
有穷自动机由有限个状态和状态之间转移和动作组成。
正则表达式引擎的实现方式有DFA和NFA两种类型。
确定性有穷状态机任意一时刻都处于确定的状态。
下面是 正则表达式a(bb)+a 对应的确定性有穷状态机的图示。
stateDiagram-v2
[*] --> s1: a
s1 --> s2: b
s2 --> s3: b
s3 --> s2: b
s3 --> [*]: a
非确定性有穷自动机的在某些时刻处于的状态是不确定的
正则表达式a(bb)+a 对应的非确定性状态机如下:
NFA1
stateDiagram-v2
[*] --> s1: a
s1 --> s2: b
s2 --> s3: b
s2 --> s1: b
s3 --> [*]: aNFA2
stateDiagram-v2
[*] --> s1: a
s1 --> s2: b
s2 --> s3: b
s3 --> s1:
s3 --> [*]: a从上面图可以知道,DFA对于每个字符只要匹配一次,所以一般来说DFA性能要更优;但是DFA所能表达的特性要少于NFA。所以大多数应用语言采用的是NFA。
各种语言的正则引擎类型
| 引擎类型 | 语言 |
|---|---|
| DFA | awk (大多数版本〉、 egrep(大多数版本)、flex、 lex、 MySQL、Procmail |
| NFA | GNUEmacs 、 Java、 grep 、 less、 more 、 .NET 、 P归bon 、 Ruby 、 PHP 、 sed |
NFA在某些时刻的状态是不确定的,NFA引擎在有多个状态的时候,会先记录下这些状态备用,然后才会选择某个状态尝试,如果尝试失败,再回退回去。
例如对于 ".*" 这个正则表达式
对于"aaaa" deeadd 这个字符串,NFA 引擎会先匹配到字符串末尾,但是发现末尾没有"则会一直回退,知道能够匹配。最后才能匹配"aaaa"
所以对于"aaaa" dddd" 最终匹配的是整个字符串 "aaaa" dddd"
标准匹配量词(?、*、+,以及{min,max})都是“匹配优先”的。
如果需要忽略优先,则需要在对应后面加上一个问号?
例如如果使用 ".*?" 则可以匹配到 "aaaa" 这个字符串
| 匹配优先量词 | 忽略优先量词 | 限定次数 |
|---|---|---|
| * | *? | 可能不出现,也可能出现,出现次数没有上限 |
| + | +? | 至少出现1次,出现次数没有上限 |
| ? | ?? | 至多出现1次,也可能不出现 |
| {m,n} | {m,n}? | 出现次数最少为m次,最多为n次 |
| {m,} | {m,}? | 出现次数最少为m次,没有上限 |
| {,n} | {,n}? | 可能不出现,也可能出现,最多出现n次 |
regexbuddy
《精通正则表达式》
《正则指引》
https://github.com/ziishaned/learn-regex/blob/master/translations/README-cn.md
维基百科
第1集 从物物交换到比特币
关键词:货币 稀缺性 一般等价物 价值 信用背书
纸币-->电子记账--->只有银行有记账权-->金融危机中美国增发货币-->中本聪提出新型支付体系-->任何人都可以记账
第2集 什么是比特币
关键词:中本聪 资产 点对点 去中心化
2140年发行完毕。企业比如微软接收比特币支付。比如可以直接用比特币购买外星人电脑。
第3集 比特币白皮书
关键词:电子现金系统
比特币是一种去中心化的电子现金系统,在没有中心机构的情况下解决恒定货币的发行以及流通问题。信息公开透明,每笔转账信息都会被记录。
第4集 第一个比特币诞生
关键词:
诞生于2009年1月4日。中本聪在芬兰赫尔辛基的服务器上创建了第一个比特币。
第5集 谁是中本聪
关键词:中本聪
中本聪是比特币的开发者以及创始者。但是没有确定是谁。
第6集 密码朋克是什么的?
关键词:
一套加密的电子邮件系统。用户约1400人。讨论数学、哲学、计算机技术等等。包括许多IT精英。
第7集 比特币是怎么发行的?
关键词:
比特币没有特定的发行机构,而是依靠去中心化的发行机制。每10分钟全体矿工计算一道题目,最新计算出答案的矿工,获得记账权,并且获得一部分奖励。
第8集 披萨居然卖到3亿元
关键词:比特币披萨日
在2010年5月22日。美国程序员拉丝勒用10000个比特换取了2个25美元的披萨。按照当前比特币的价格计算,当时的10000个比特币价格不言而喻啊哈哈。
第9集 中本聪的继任者
关键词:加文安德烈森
中本聪对加文有了信任之后,将加文的邮箱放到了比特币首页,并退到了幕后。加文组建了比特币核心开发团队,致力于提供比特币的易用性以及修复安全漏洞。
第10集 早期比特币
关键词:比特币水龙头
2010年年底,加文为了提供比特币的知名度,花费了50美元购买了10000个比特币,并创建了比特币水龙头网站,每个访问网站的人可以获得5个比特币。比特币水龙头网站还成为了导流网站,给主要比特币网站导流获取广告费。
第11集 比特币为什么还没有挖完
关键词:记账权
比特币通过调整难度系数保证比特币不被太快挖完。如果全网算力不断增长,比特币将很快被挖完。
中本聪设计矿工挖矿挖出比特币的难度为2016个区块调整一次。
第12集 比特币如何总量恒定
关键词:2100万区块 比特币细分 每10分钟
比特币是一种通缩型的虚拟货币。比特币设计比特币能细分到小数点后8位,每个区块记录50个比特币,每21万个区块之后产量减半。比特币每10分钟产生一个区块,21万个区块大概是4年的时间,截止2017年比特币产量已经减半2次。大约在2045年99.95%的比特币将发行完毕,到2140比特币无法再细分,发行完毕。这个机制激励着矿工尽早投入比特币挖矿,比特币系统获得大量的算力以及安全性。
第13集 比特币和Q币有什么不同?
关键词: 信用背书 ,共同记账
比特币是一种去中心化的数字资产,没有发行主体。Q币是腾讯发现的电子货币,类似于电子积分,Q币需要腾讯的信用背书,并且只能用于腾讯游戏等其他业务之中。比特币是全网参与者共同记账,不需要中心机构背书,任何人都无法篡改账本。
第14集 各国对区块链资产的态度如何
关键词:态度不一 探索期
欧美国家积极监管,德国是最早将数字资产定位为私有资产的国家之一;美国CFTC将比特币定位为大宗商品。亚洲情况不一样,日本韩国积极支持;中国人民银行等七部委(中国网信办、保监会、证监会、银监会、工商总局、工业和信息化部)联合发布关于发现代币发行融资风险的公告,规定在中国
不得从事法币和代币之间的兑换业务
第15集 比特币如何转账
关键词:比特币地址 转账金额 交易费金额
比特币转账就是把比特币从一个比特币地址转移到另外一个比特币地址的过程。确定转账信息之后,交易信息会在全网广播。矿工每隔10分钟将未确认的交易打包到区块。
第16集 比特币转账需要多少手续费
关键词:竞争记账 交易费
比特币转账手续费是交易者支付给记账矿工的一笔费用,用于激励矿工记账。交易费用一般为0.001-0.0015比特币。由于区块能记录的交易有限,矿工会选择优先记账手续费高的交易。交易费用提高了门槛,有效防止区块链中充斥垃圾信息。并且能够保证比特币被挖完之后,矿工依然有动力维护比特币网络。
第17集 区块链转账按照字节收费
关键词:跨行转账 按照字节收费
银行间转账一般是按照转账金额比例来收费,跨行一般是千分之五,异地转账费用一般为千分之一或百分之一不等。比特币之间转账费用与金额无关,按照字节收费。如果你在一笔交易中转账给多个地址,那就需要多支付一些手续费,才会有矿工愿意打包交易。
第18集 比特币地址是什么
关键词:比特币地址
比特币地址是一个26-34位的字符串,看起来像乱码,每个人的比特币地址都是独一无二的。
第19集 比特币节点是什么
关键词:节点 全节点
比特币是一种节点对节点的系统,每笔交易由发起方向周围节点广播,节点收到后继续广播。拥有完整区块链账本的是全节点。全节点负责交易的广播和验证。转账发生后会由节点广播到全网,挖矿节点验证交易之后会记录到账本。 比特币的全节点数只占节点数的一部分。
第20集 从发出交易到矿工打包需要几步?
关键词:本地内存池 未确认交易池 无效交易
比特币交易发出之后,广播到全网,挖矿节点接收到之后会将其放入到本地内存池,并对其进行验证,比如该笔交易话费的比特币是否是未被花费的交易,确认之后则放入到未被确认的交易池;如果验证失败则被认为是无效交易。矿工打包是从未确认交易池中获取交易进行打包。
21 比特币的数字签名
关键词:数字签名 摘要 非对称加密技术
比特币的数字签名只有转出人才能生成的一段防伪造的字符串,通过验证该字符串一方面证明该信息是由该转出人发起的,另一方面证明该消息未被篡改。数字签名由数字摘要和非对称加密技术组成。首先通过数字摘要技术将信息转换成固定长度的字符串,然后用自己的私钥对摘要进行加密,形成数字签名;完成后需要将完整信息和数字签名一起广播给矿工。矿工用发送者的公钥进行验证,验证成功则说明该笔交易确实是发送者发起的且信息未被篡改。非对称加密技术是说加密技术中加密的私钥和解密的公钥不一致,真实转账过程只需要输入私钥就可以了。
22 比特币交易和找零机制
关键词::找零机制
比特币可以一次把多个地址的余额转出,也可以一次转给多个地址。比如你要支付给牛牛5个比特币,但是你的ABC三个地址里面分别只有1/2/2个比特币,不足以支付5个比特币;这时候你可以发起一笔转账,把三个地址的比特币转出去。另外如果你的比特币地址有5个比特币,你只需要转1个比特币给牛牛。你可以发起一笔交易,转1个比特币给牛牛,剩余4个比特币转回给自己。
23 挖坑是什么?
关键词: 挖坑 矿工 账本
挖矿是将比特币系统中一段时间未确认的交易进行确认,并记录到区块链上。挖坑就是记账的过程。成功抢到记账权的矿工会有一笔奖励。
24 比特币怎么挖坑?
关键词:挖坑
每10分钟全网矿工计算一道算术题,谁先算出答案,谁就能获得记账权。如果你要挖矿,那你要准备好矿机/比特币地址/挖坑软件。当前单个矿机很难挖到比特币,需要加入到矿池。
25 矿工怎么挖坑?
关键词:虚拟货币
从事虚拟货币挖坑的人被称为矿工。挖坑由电脑执行特定的运算,矿工只要保证电力和网络就行即可。
26 矿机是什么?
关键词:矿机 算力
矿机由散热片和风扇组成,是用专用芯片作为核心。
27 比特币挖坑的进化史
关键词:BM1387芯片
四个阶段:CPU /GPU/矿机/矿池挖坑。
28 矿场长什么样:
关键词:矿场 机架 静音矿场
矿机损坏率高,噪音大
29 矿池怎么挖坑
关键词:算力
矿池将分散在全球的矿工以及矿场的算力进行联结,一起挖坑。矿池负责信息打包。矿池的算力占比大,因此挖到比特币的概率高。矿池挖坑所获得受益按照矿工贡献的算力按比例分配。全球有鱼池/蚁池/币网/国池/BITFURY几大大矿池,钱
30 算力是什么?
关键词:哈希碰撞
在通过挖矿得到比特币的过程中,我们需要找到其相应的解,算力可以简单地理解为计算能力。一台矿机一般有14T的算力。
31 竞争记账是什么?
关键词:
比特币系统采用的是竞争记账的方式;它解决了在去中心化的系统中如何保证账本一致性的问题。
32 如何投资区块链资产?
关键词:场内交易 场外交易 中心化交易平台 去中心化交易平台
33 交易平台投资区块链
关键词:
相对于挖矿,在区块链平台购买是主流的方式(场内交易)
35 区块链资产场外交易
关键词:场外交易
比特币拥有着双方直接进行交易
36 去中心化交易平台
关键词:
去中心化交易平台的每一笔交易都通过区块链进行,需要等待区块链确认。去中心化平台的交易速度很慢。在全球数字化资产交易平台上只占0.03%。
37 币币交易是什么?
关键词:币币交易平台
用一种区块链资产定义另外一个资产的价格。
38 比特币钱包是干嘛的?
关键词:
比特币钱包存放了比特币的地址以及对应的私钥。
39 冷钱包热钱包
关键词:私钥
冷钱包是指网络不能访问到你的私钥的钱包;热钱包是互联网可以访问你的私钥的钱包。
无论是冷钱包还是热钱包,只要其他人知道了你的比特币私钥,就能转走你的比特币。
40 全节点钱包与轻钱包
关键词:
根据区块链数据的维护方式和钱包的去中心化程度,我们可以把钱包分为全节点钱包/轻钱包以及中心化钱包。
41 比特币可用于支付吗?
关键词:比特币钱包
在部分国家可以支持,消费者向第三机构支付比特币,第三方机构向商家支付法币。扫码之后,双方会显示比特币的实时汇率,确认之后再进行支付。
42 区块链和比特币是什么关系?
关键词:账本 区块链
比特币是区块链的第一个应用,区块链可以类似于账本,每个区块就是账本中的一页,不同区块之间按照密码学原理进行链接,所有的区块按照顺序链接在一起。
43 区块链技术发展史
关键词:
2015年经济学人发表文章,重塑世界经济的区块链技术。2017年9月中国政府网发布文章《我国区块链产业有望走在世界前列》,公开支持区块链技术。
44 区块链制作信用
关键词:技术集成
比特币通过非对称加密技术、时间戳、共识算法等。解决了双重支付和拜占庭将军问题。非对称加密保证了私钥的安全性,时间戳保证了区块按顺序连接成链,工作量证明解决了如何保证公平分发2100万个比特币的问题。
45 区块链连接成区块链
关键词:哈希值
区块里面存有交易,区块链是由密码算法结构连接成的,每个区块都是在前一个区块的基础上生成的。在比特币中每个矿工必须要在前一个区块生成之后才能继续下一个随机数的计算,保证了比特币挖矿的公平性。
46 区块链记录了哪些信息?
关键词:区块头 时间戳 随机数 难度目标 交易详情 交易计数器 区块大小
每个区块链主要记录了区块头、时间戳、随机数等
47 时间戳是什么?
关键词:时间标记 公证人
时间戳使得区块链上面每笔交易都有时间标记,时间戳在区块链中扮演了公证人的角色。比
48 最长的区块链才是正确的区块链
关键词:最长区块链
节点永远认为最长链是正确的区块链,由于区块链账本的唯一性,如果给你转账的比特币交易不记录在区块链上,那就有可能会有财产损失。我们通常要求比特币在转账被打包之后,还需要经过6个区块的确认,确保不会矿工不会再回到另外一个分叉挖矿时,才算真正的打包成功。
49 区块链如何分类?
关键词:私有链 公有链 联盟链
公有链公开透明,每个人都有记账权。联盟链是群体或者组织内部使用的区块链,需要预先指定某几个节点作为记账人。私有链完全完全封闭,仅仅采用区块链技术记账,记账权并不公开。
50 区块链资产的全球流通
关键词:
比特币资产有几大特点,其中一个就是全球流通。
参考链接:
https://zh.wikipedia.org/wiki/%E5%90%8C%E6%80%81%E5%8A%A0%E5%AF%86
http://blog.csdn.net/Canhui_WANG/article/details/51882445
https://www.zhihu.com/question/27645858
摘要:
一句话描述:同态加密(homomorphonic encryption)是指不需要密钥的情况下,直接对密文进行代数操作得到密文,其解密获得的结果和明文进行操作同样的操作获得的结果一样。
补充说明:也就是同态加密提供了一个对加密数据进行处理的能力,使得我们能够实现数据处理安全。而之前密码学关注的都是数据存储安全。
用途:数据处理方不需要知道数据处理的明文信息。特别适合在云计算场景适用。可以借助云计算平台的计算资源而又不公开数据。
当前问题:效率比较低。
云计算场景描述:

同态加密分类:
全同态加密: 支持给定的任意函数f
部分同态加密:只支持特定的函数f.
最近在思考解决方案的构造方法,一套解决方案,不仅仅是一个产品,而是众多产品为解决某一个应用场景的组合。链接不通的产品,涉及到的不仅仅是独立产品的部署,还涉及到产品之间的相互连通。这里面所涉及到的事情就多了。独立产品的安装涉及到网络规划、操作系统安装、应用安装等;网络互联涉及到主机网络配置、主机防火墙配置、路由配置、交换机配置、中间防火墙配置等等;另外还涉及到应用高可用、负载均衡、证书管理、网络质量管理等等。
那么,如果是从一个产品的维护的角度看,你会希望在输出这样一份解决方案的时候,同时输出什么样的文档或者资料,用于辅助产品运维呢?这样一个解决方案的构建思路是怎么样的呢?
安装git工具
1、首先下载zlib, http://zlib.net/; git工具:https://github.com/git/git/archive/master.tar.gz。下载后是两个tar.gz包
(git-master.tar.gz,zlib-1.2.8.tar.gz)
2、上传到linux服务器,解压两个压缩包.
3、执行 ./configure && make && make install 安装zlib.
4、执行以下命令编译git make NO_OPENSSL=YesPlease NO_CURL=YesPlease prefix=/usr all
5、执行以下命令安装git sudo make NO_OPENSSL=YesPlease NO_CURL=YesPlease prefix=/usr install
6、对需要使用git的用户配置环境变量:
在主目录的.bash_profile或者/etc/profile文件加入设置环境变量
export PATH=/usr/libexec/git-core:$PATH
然后重启登录或者source一下该文件使其生效。